Jul 24, 2021
GCP VM Instance Stop Experiment for LitmusChaos
This blog is a beginner-friendly guide for the GCP VM Instance Stop chaos experiment for LitmusChaos. The experiment causes the shutdown of one or more GCP VM instances for a specified duration of time and later restarts them. The broad objective of this experiment is to extend the principles of cloud-native chaos engineering to non-Kubernetes targets while ensuring resiliency for all kinds of targets, be it Kubernetes or non-Kubernetes ones, as a part of a single chaos workflow for the entirety of a business.
At the time of writing this blog, the experiment is available only as a technical preview in the chaos hub, but in the upcoming releases, the experiment will surely become an integral part of the chaos hub. That being said, we can still access and execute the experiment without any problem, as I am about to show you in this blog.
Pre-Requisites
Before we begin with the steps of the experiment, let’s check the pre-requisites for performing this experiment:
- A GCP project containing the target VM instances
- A GCP Service Account having sufficient permissions to stop or start the VM Instances
- A Kubernetes cluster with Litmus 2.0 installed
STEP 1: Updating The Chaos Hub
Browse and log in to your Litmus portal. You should be on the dashboard.
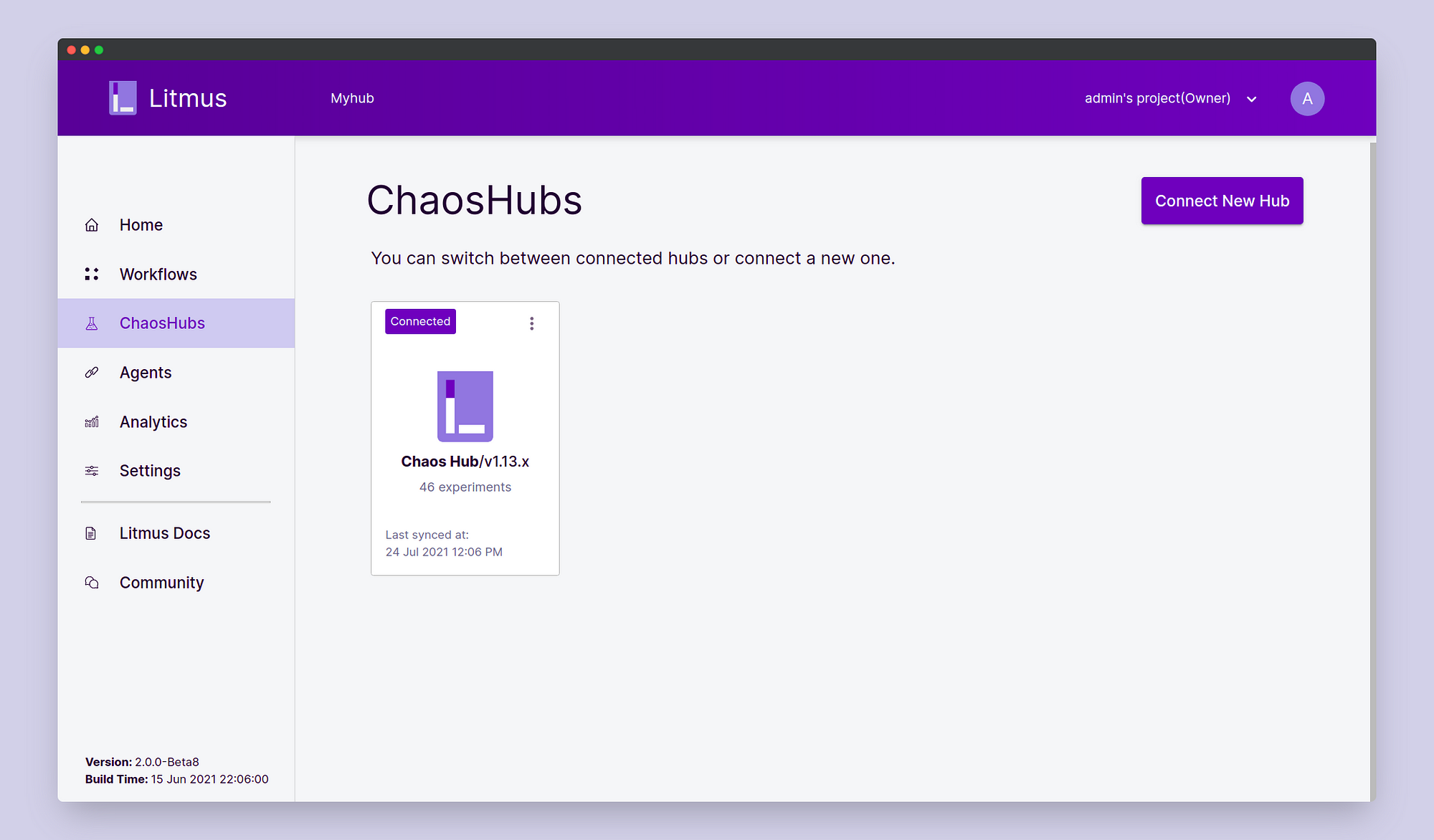
Select ChaosHubs. Here you’d be able to see the default ChaosHub.
Choose to Edit the default Chaos Hub and instead of the v1.13.x branch,
choose the master branch.
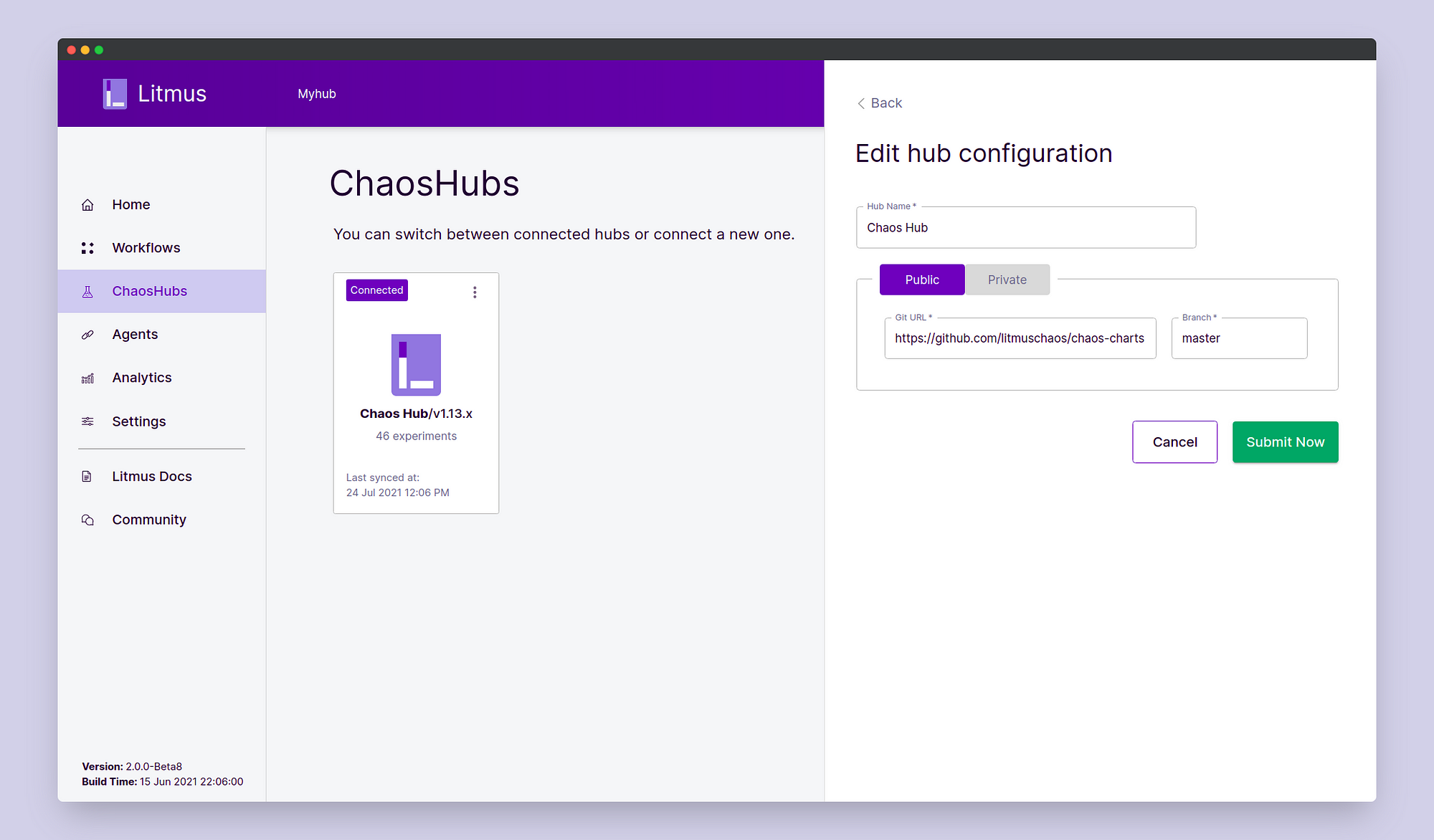
Click Submit Now. Now you’d be able to access all the experiments, even those under the technical preview. To confirm that the experiments have been added successfully, click on Chaos Hub and view the Chaos Hub.
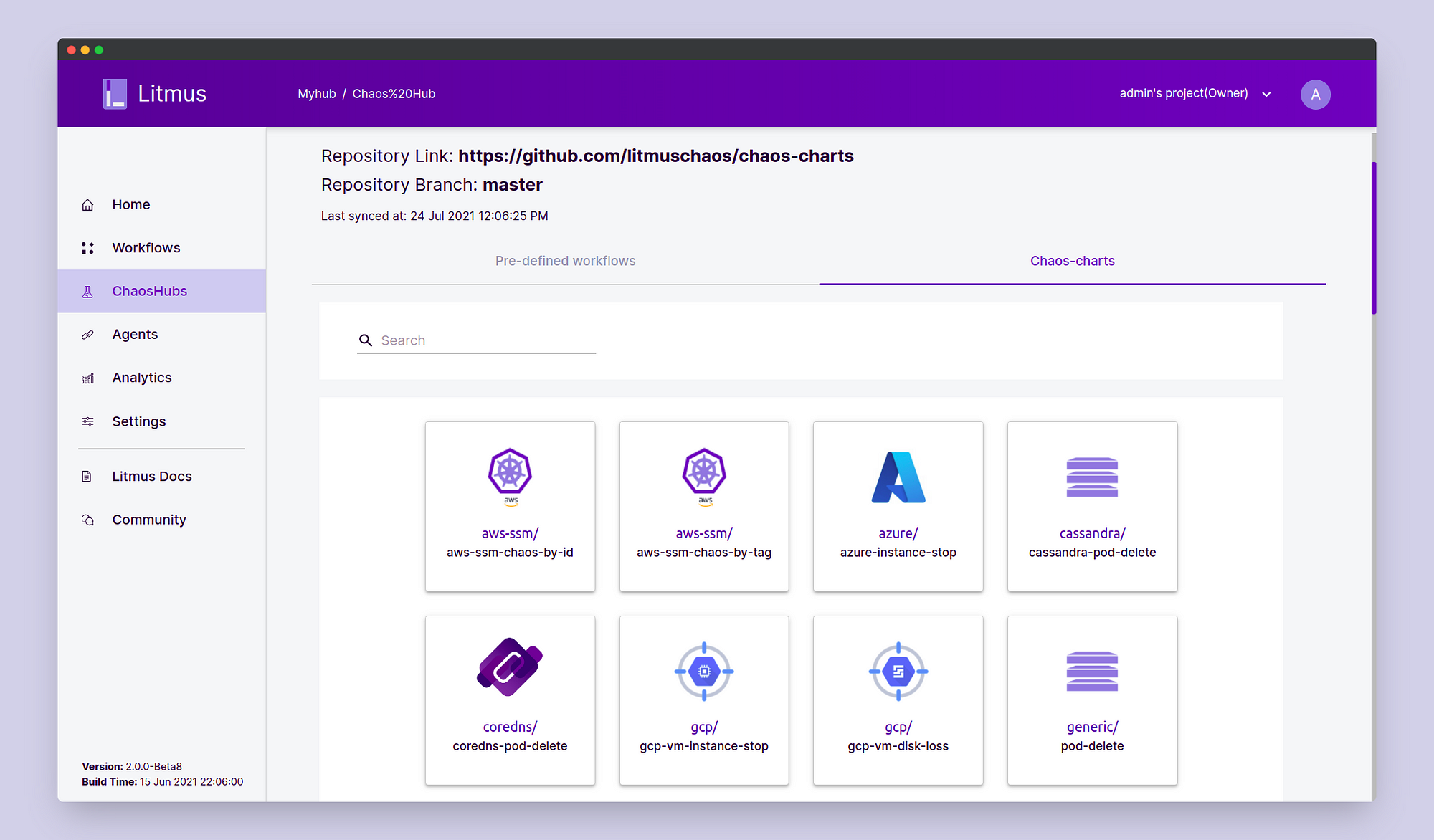
You should see the GCP Experiments listed here. Now we are all set to begin the steps of the experiment.
STEP 2: Setting Up the Chaos Experiment
We’d be using the experiment docs to help us with a few steps.
In this demo, we will inject chaos into two VM instances named
test-instance and test-instance-1, belonging to the zones
us-central1-a and us-central1-b respectively, belonging to the GCP
project “Litmus GCP Instance Delete” with the ID of
litmus-gcp-instance-delete.
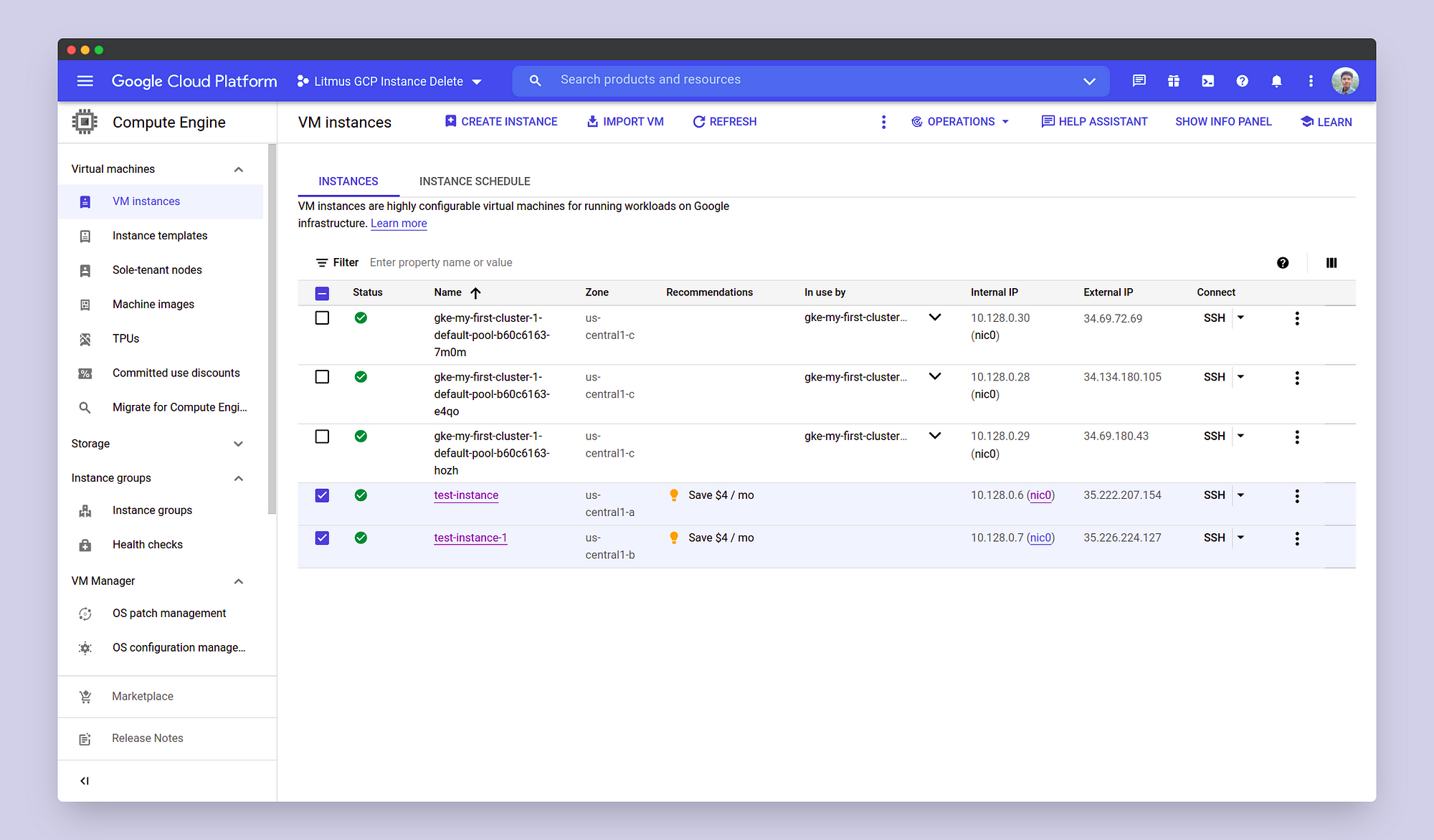
Please notice that the instances are in a running state initially, before
the injection of the chaos. Now that we have our instances ready, we can
set up our experiment. Before scheduling the chaos experiment, we need to
make the GCP Service Account credentials available to Litmus, so that the
instances can be shut down and later started as part of the experiment. To
do that, we’d make a Kubernetes secret named secret.yaml as follows:
apiVersion: v1 kind: Secret metadata: name: cloud-secret type: Opaque stringData: type: "service_account" project_id: "litmus-gcp-instance-delete" private_key_id: "9e0jacc5e0abb74f3426df51c0ca5065904c6beb" private_key: -----BEGIN PRIVATE KEY-----\nMIIEvgIBADANBgkqhkiG9w0BAQEJAASCBKgwggSkAgEAAoIBAQD1JSTjKKN5CCGF\nUsWnaCHfFOReX6wDT+toYz065z5t4cYq3wb/RUGJz4q6n0Z> client_email: "experiment-demo@litmus-gcp-instance-delete.iam.gserviceaccount.com" client_id: "123476663820197864518297" auth_uri: "https://accounts.google.com/o/oauth2/auth" token_uri: "https://oauth2.googleapis.com/token" auth_provider_x509_cert_url: "https://www.googleapis.com/oauth2/v1/certs" client_x509_cert_url: "https://www.googleapis.com/robot/v1/metadata/x509/experiment-demo%40litmus-gcp-instance-delete.iam.gserviceaccount.com"
The format of this secret is also available in the experiment docs. Make
sure the name of the secret is cloud-secret and replace the respective
fields of the secret with your own service account credentials. Once done,
apply the secret in the litmus namespace using the command:
kubectl apply -f secret.yaml -n litmus
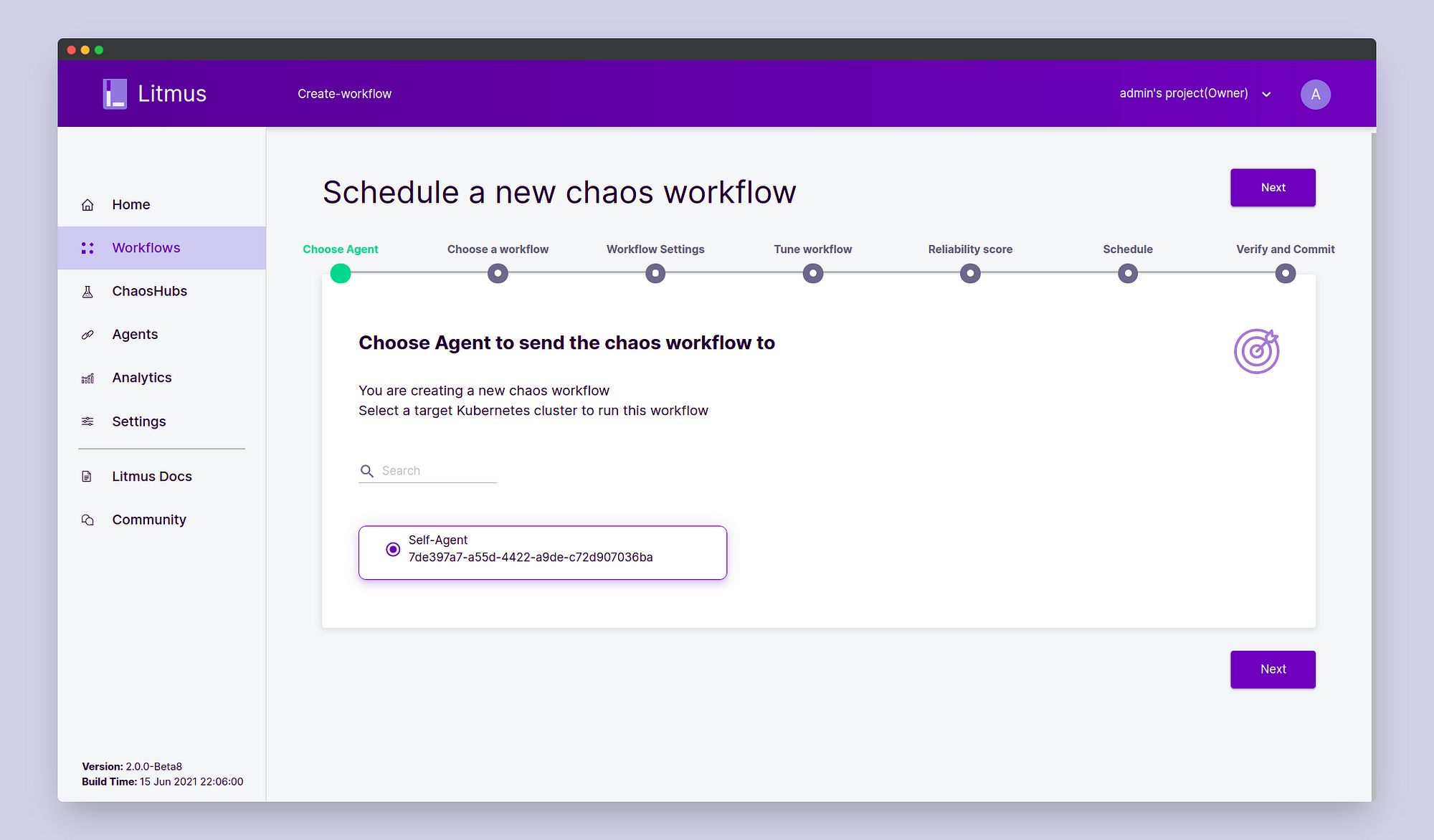
Once the secret is applied, we’re all set to schedule our experiment from the Litmus portal. In Dashboard, click on the Schedule a Workflow button. In the workflow creation page, choose the self-agent and click Next.
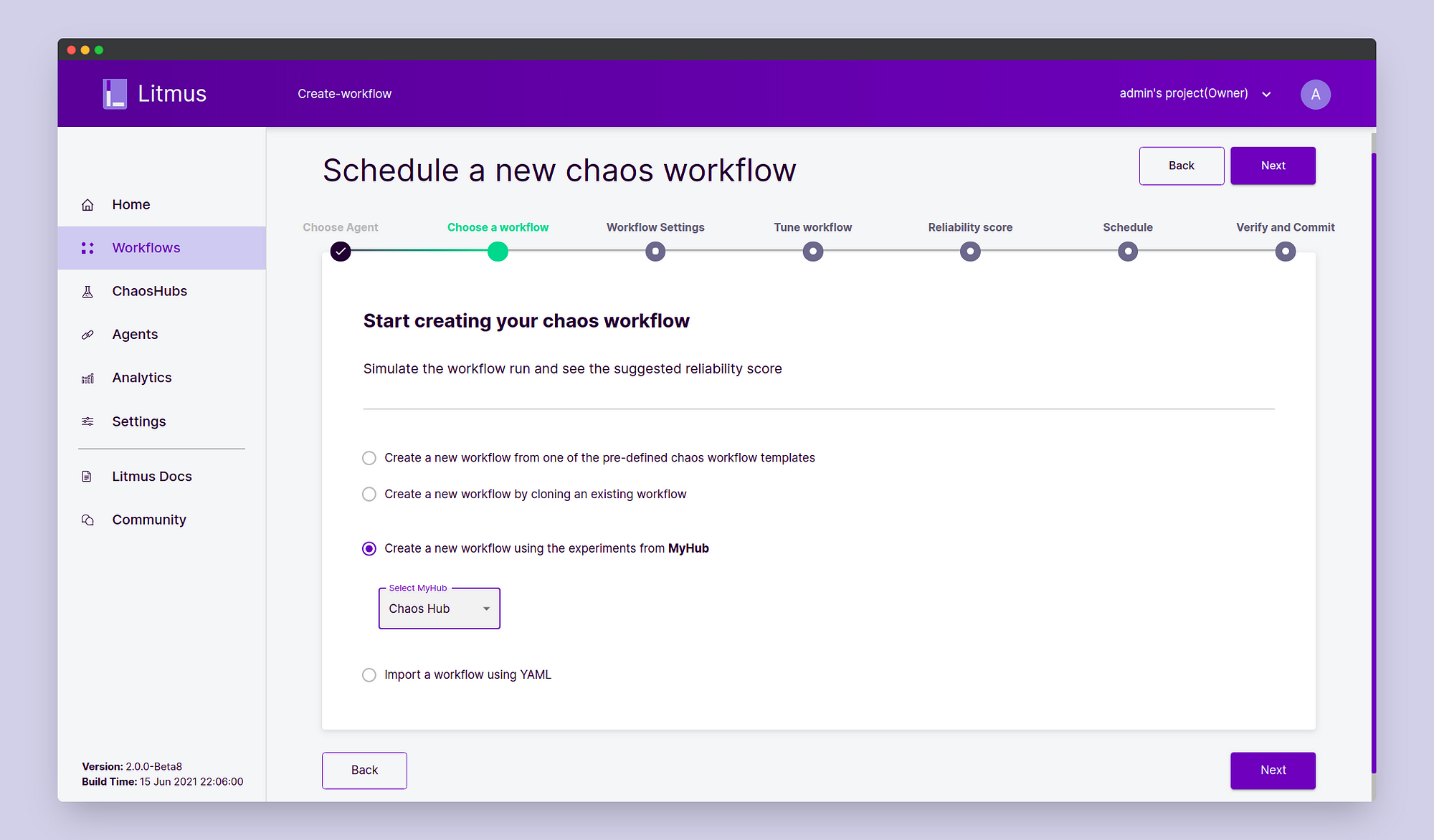
In the Choose a Workflow page, select “Create a new workflow using the experiments from MyHub” and select Chaos Hub in the dropdown. Then click Next.
In the Workflow Settings page, fill in the workflow name and description of your choice. Click Next.
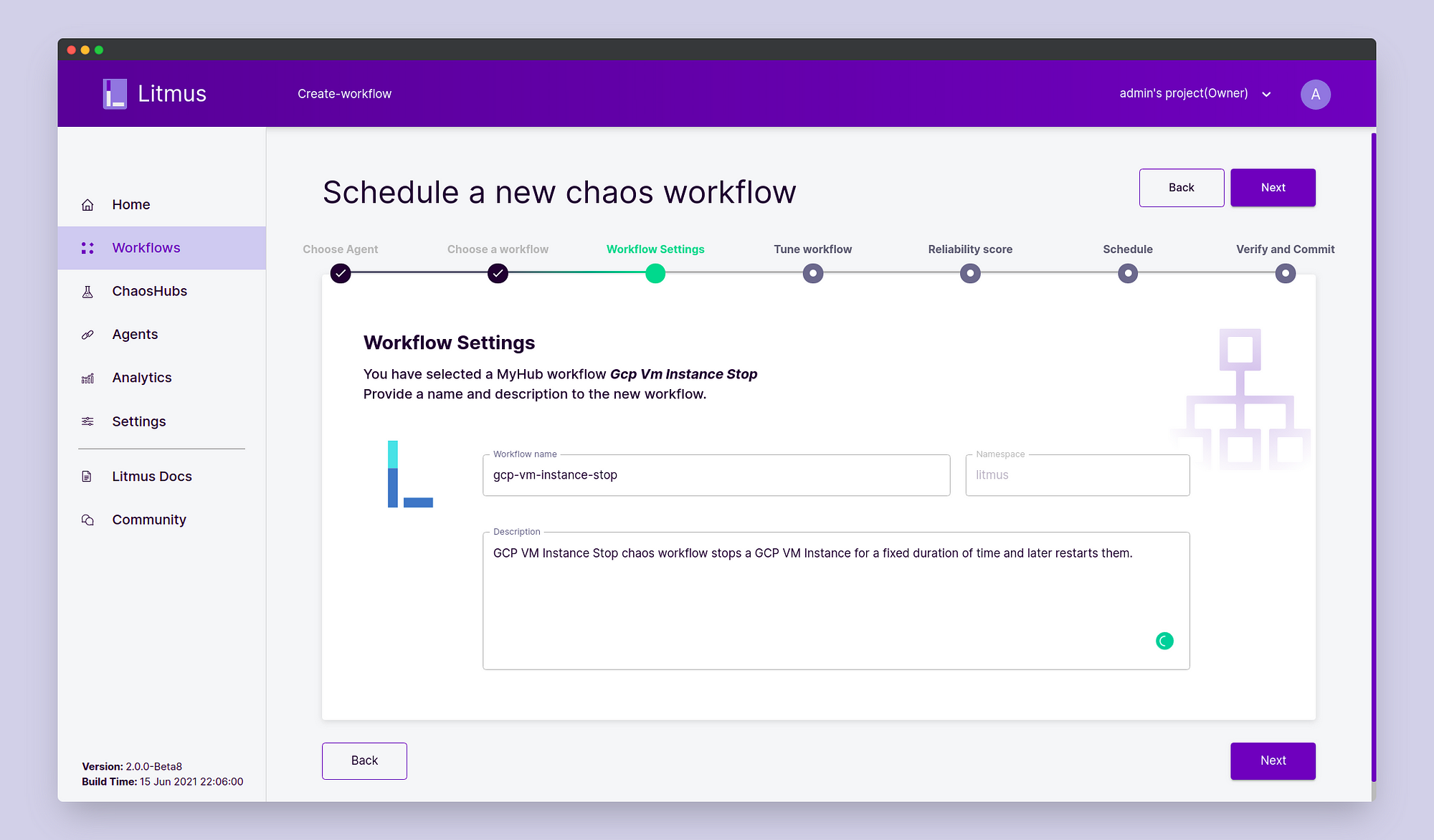
In the Tune Workflow page, click on “Add a new experiment” and choose
gcp/gcp-vm-instance-stop.

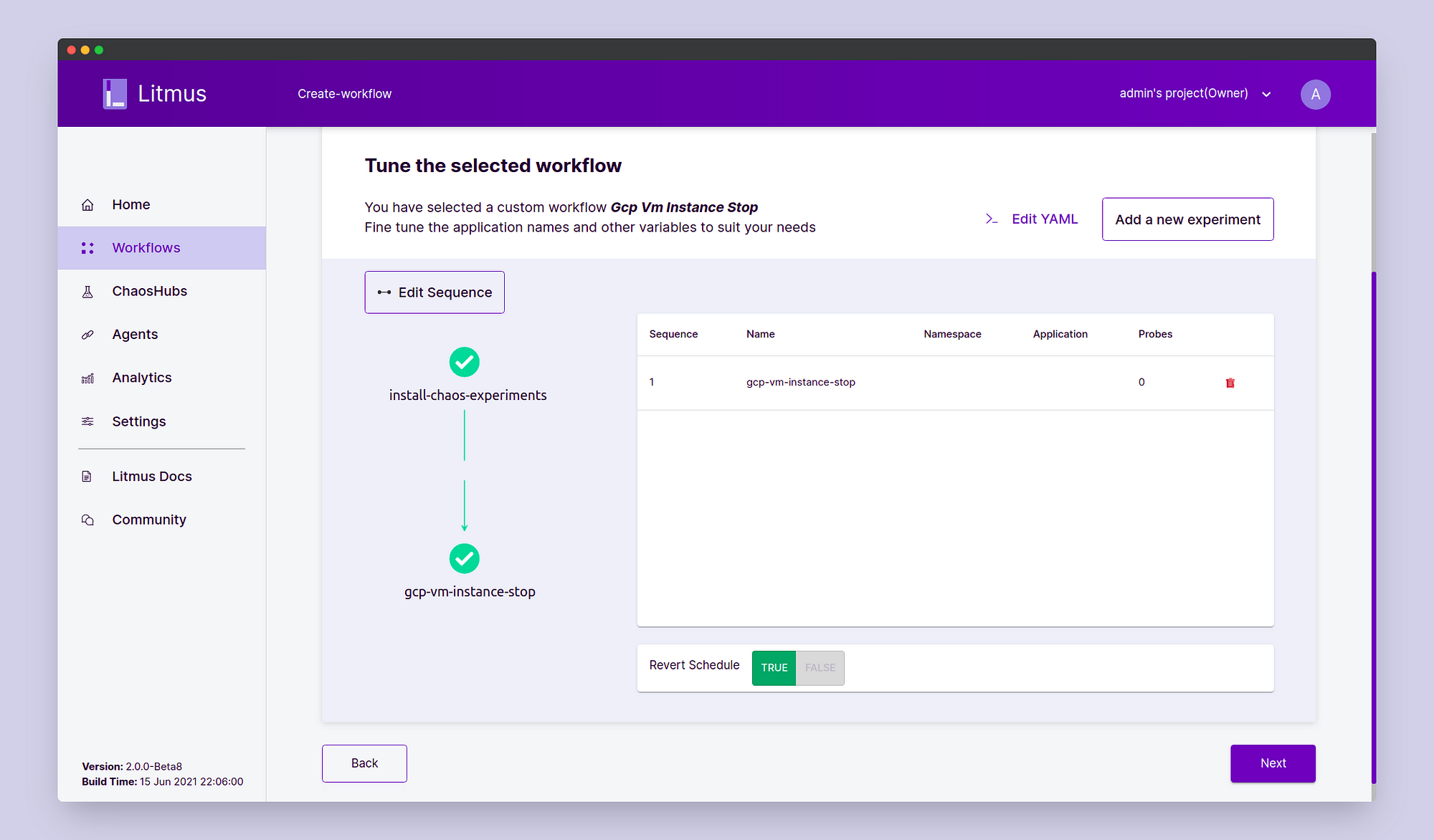
Click Done. Notice that the experiment has been added to the experiment graph diagram. Now click on “Edit YAML”. Here we will edit the workflow manifest to specify the experiment resource details.

Scroll down to the manifest of the ChaosExperiment:
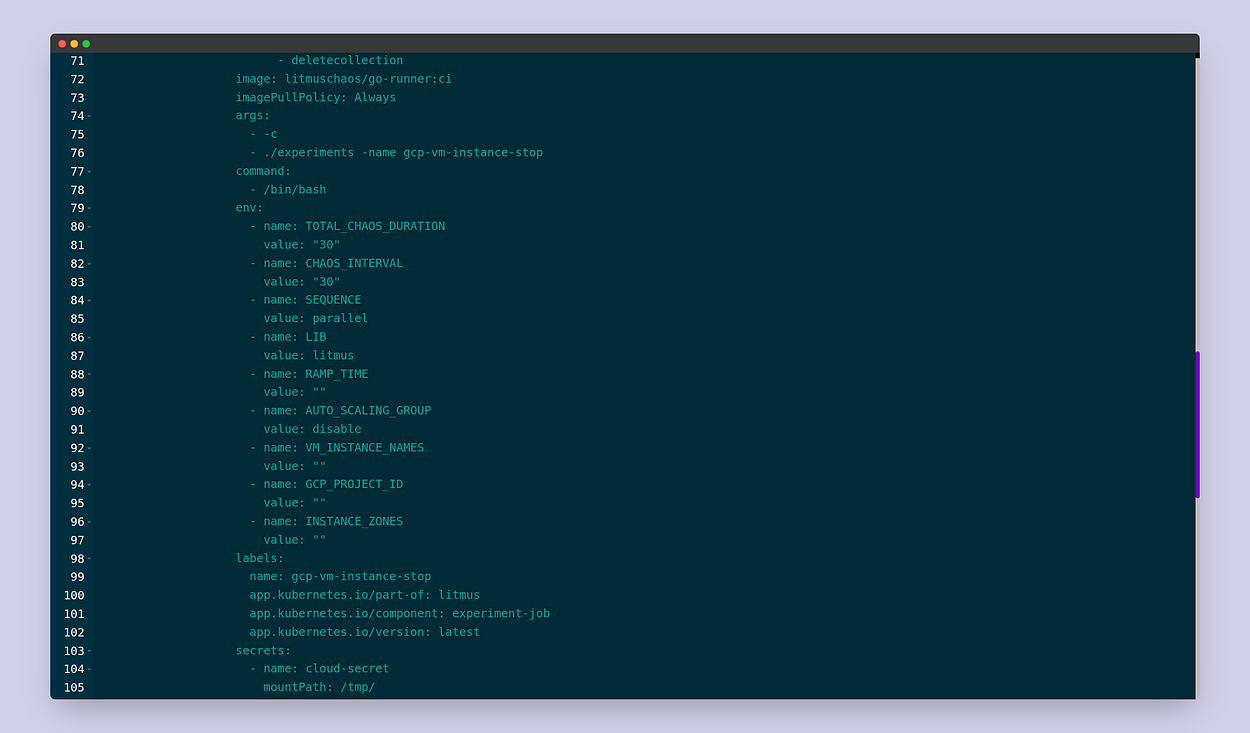
Notice that the name of the secret that we had previously created is being
passed to the ChaosExperiment to be mounted at the path /tmp/.
Scroll further down and similarly fill in the relevant experiment details
in the manifest of the ChaosEngine as follows:
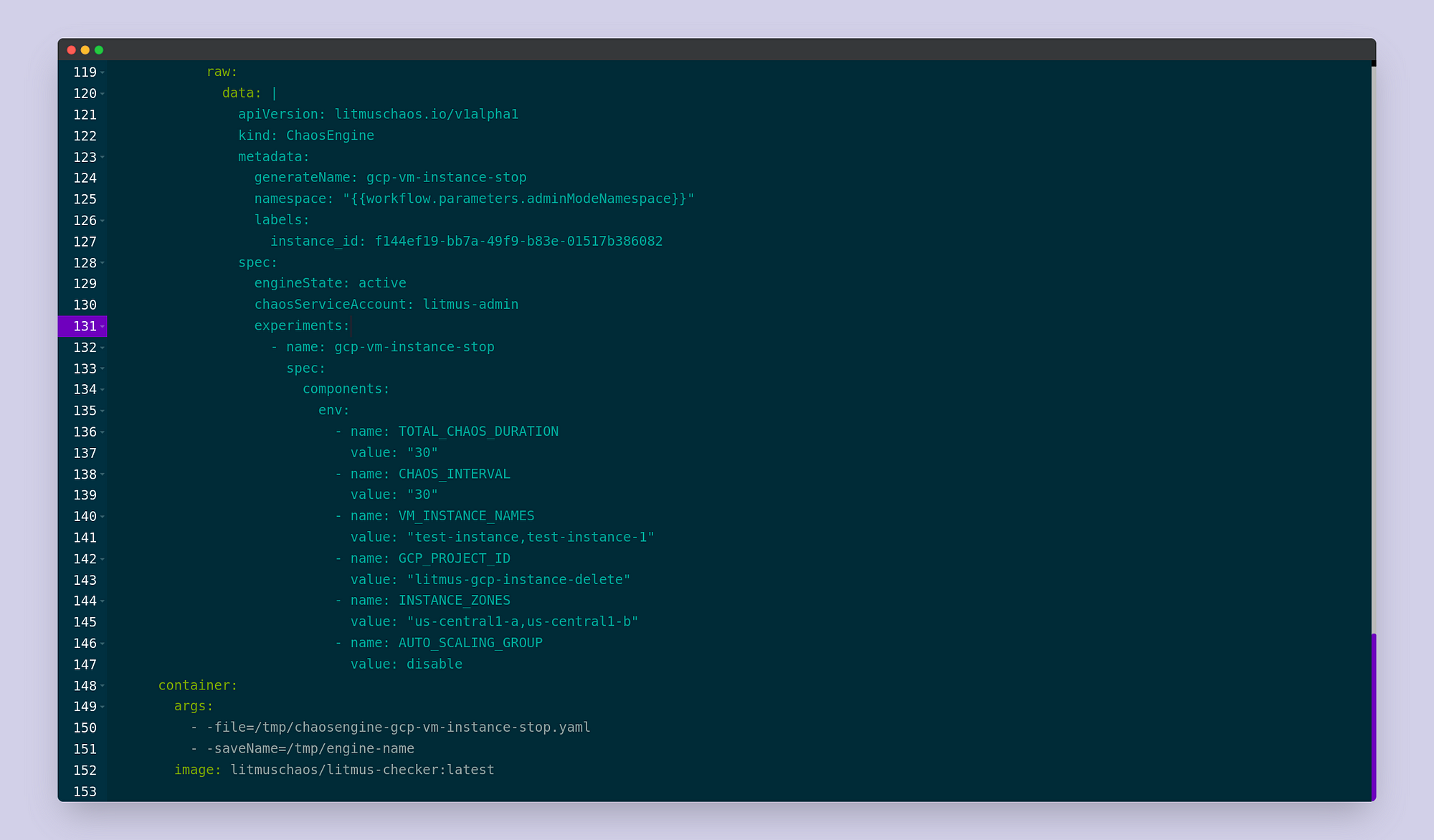
Please take note that the zone for each target instance is to be mentioned
in INSTANCE_ZONES in the same order of the VM_INSTANCE_NAMES. If you
like, feel free to modify the other parameters of the experiment such as
the RAMP_TIME, TOTAL_CHAOS_DURATION, etc. As you would have noticed,
some of the experiment tunables are common for both the ChaosEngine and
ChaosExperiment, and the values of ChaosExperiment get overridden by
that of the values of the ChaosEngine if they differ in both the
manifests. Once done, click Save Changes. We’ve now specified all the
experiment details and are ready to go to the next step. Click Next.
In the Reliability Score, we will use the default score of 10. Click Next.
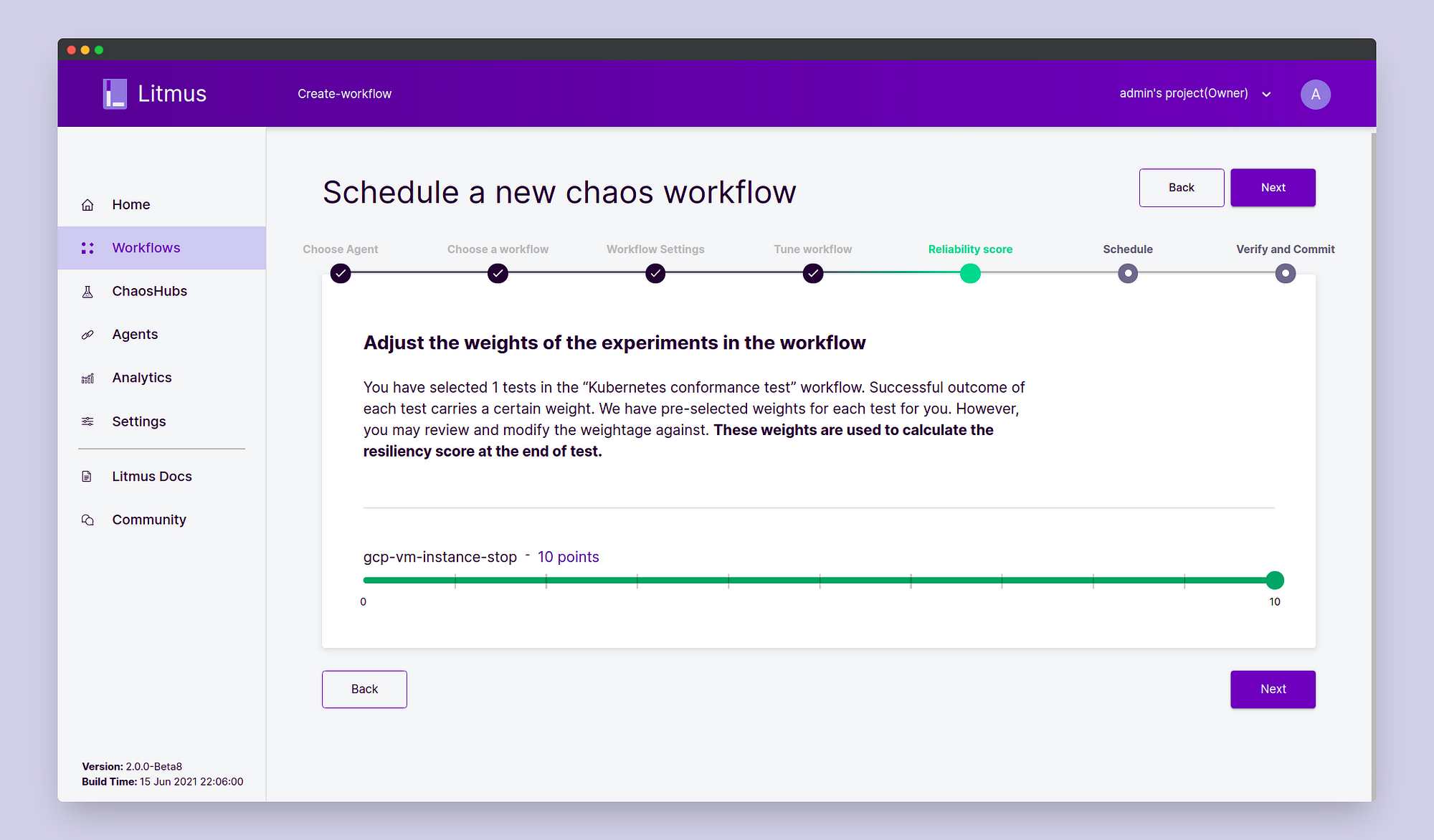
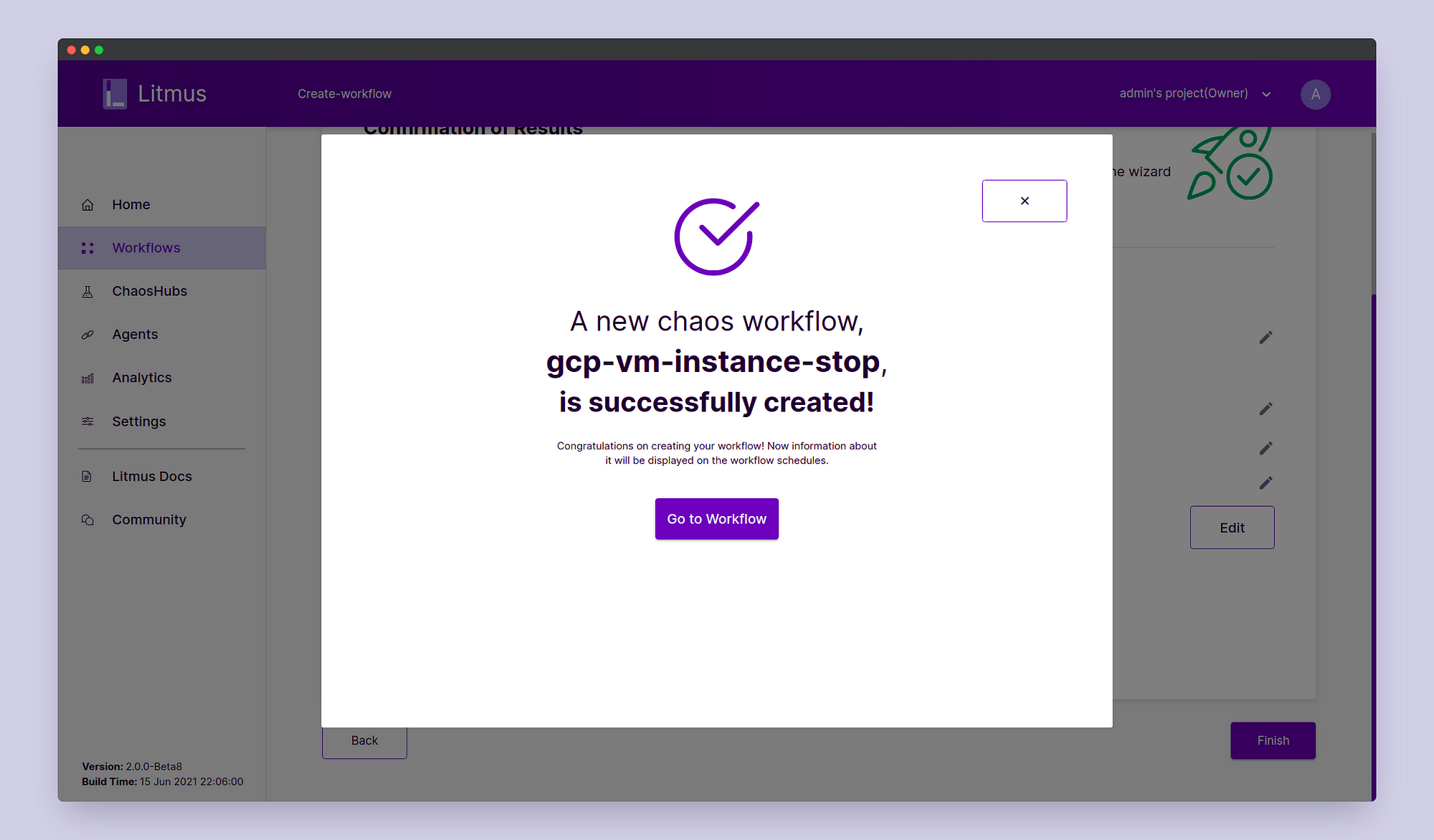
In Schedule, click Schedule Now. Click Next. On the Verify and Commit page verify all the details and once satisfied click on Finish. We’ve successfully scheduled our chaos experiment.
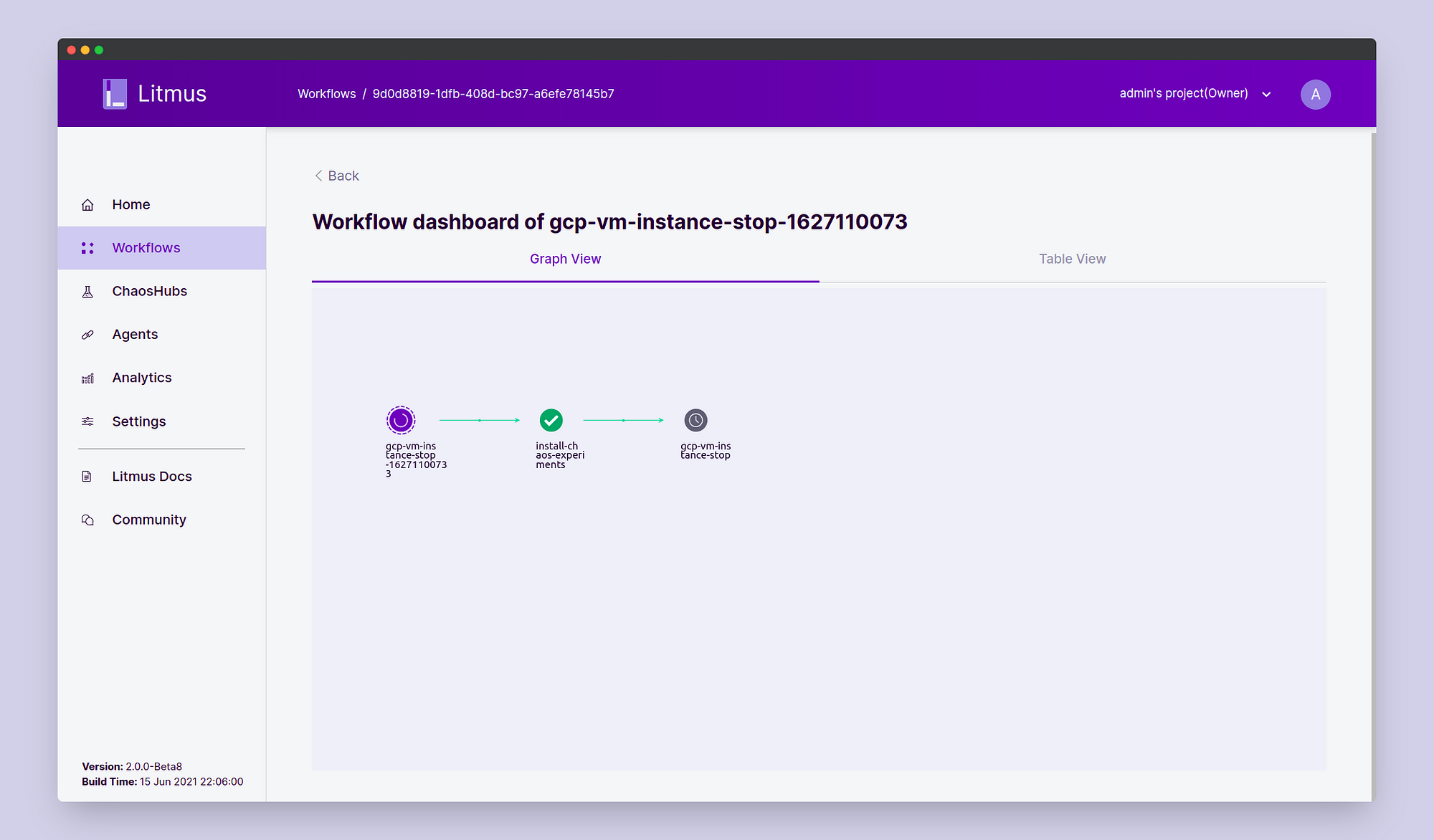
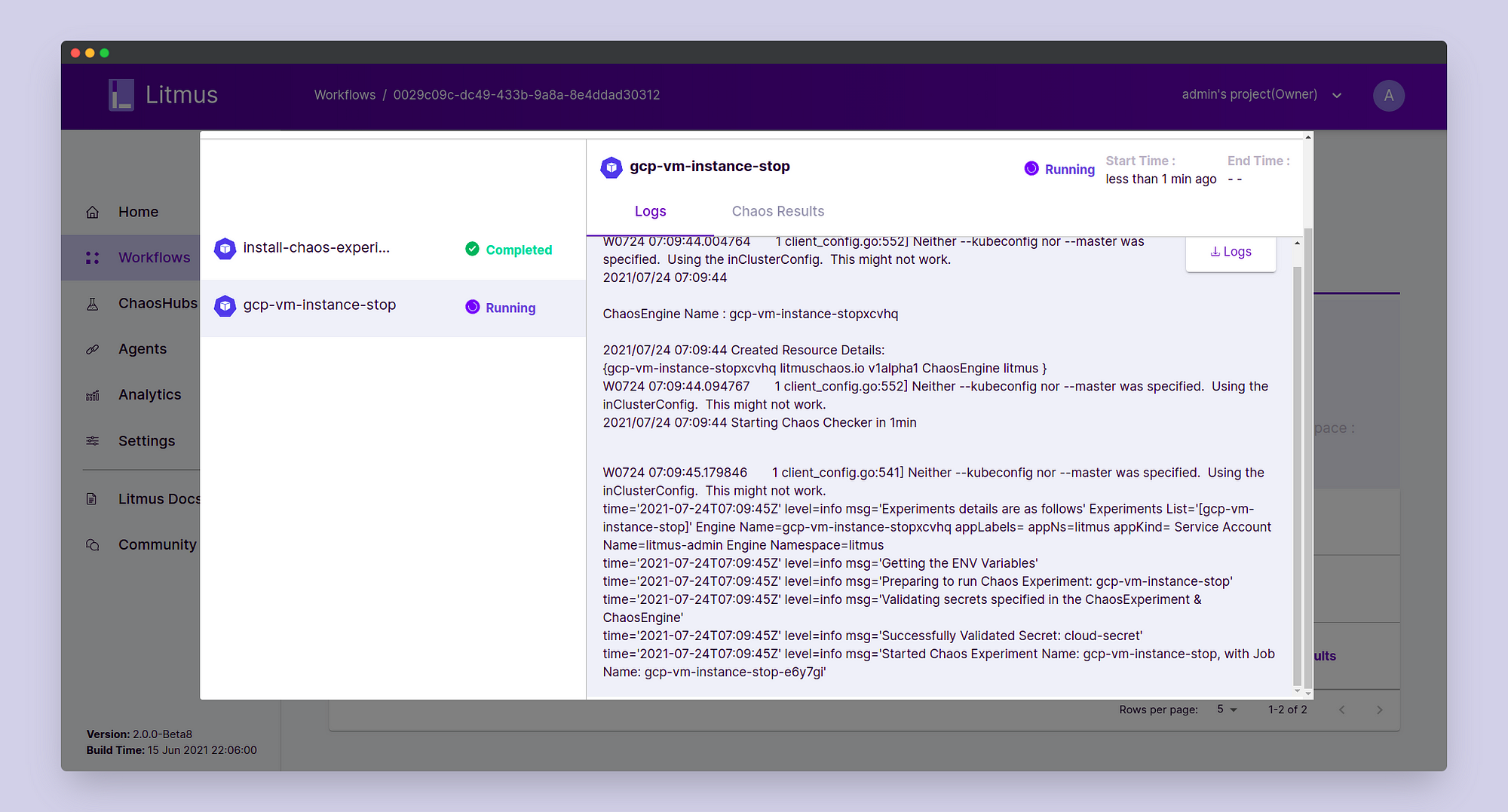
STEP 3: Observing the Chaos
Click on Go to Workflow and choose the workflow that we just created. Here we can observe the different steps of the workflow execution including chaos experiment installation, chaos injection, and chaos revert.
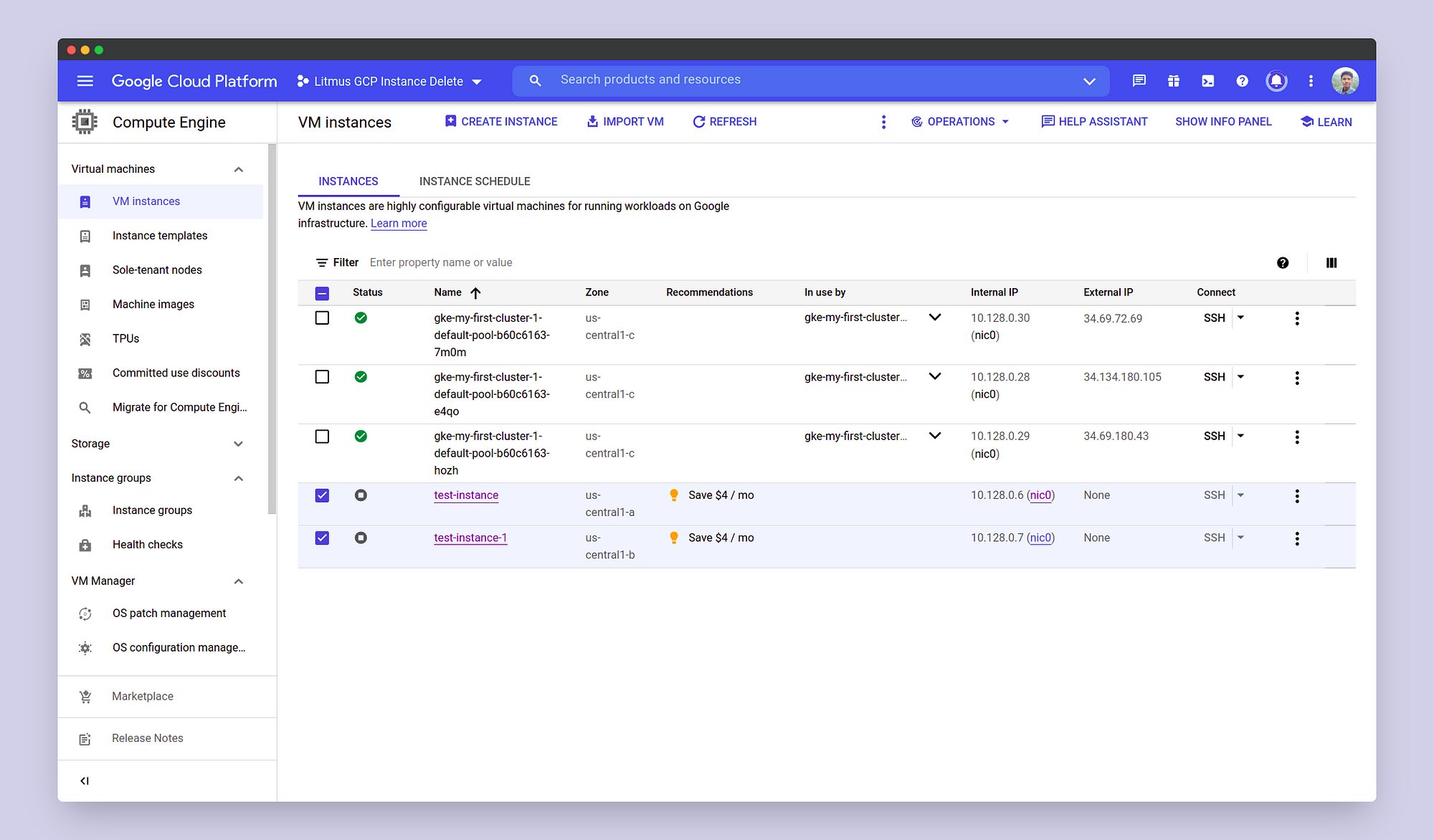
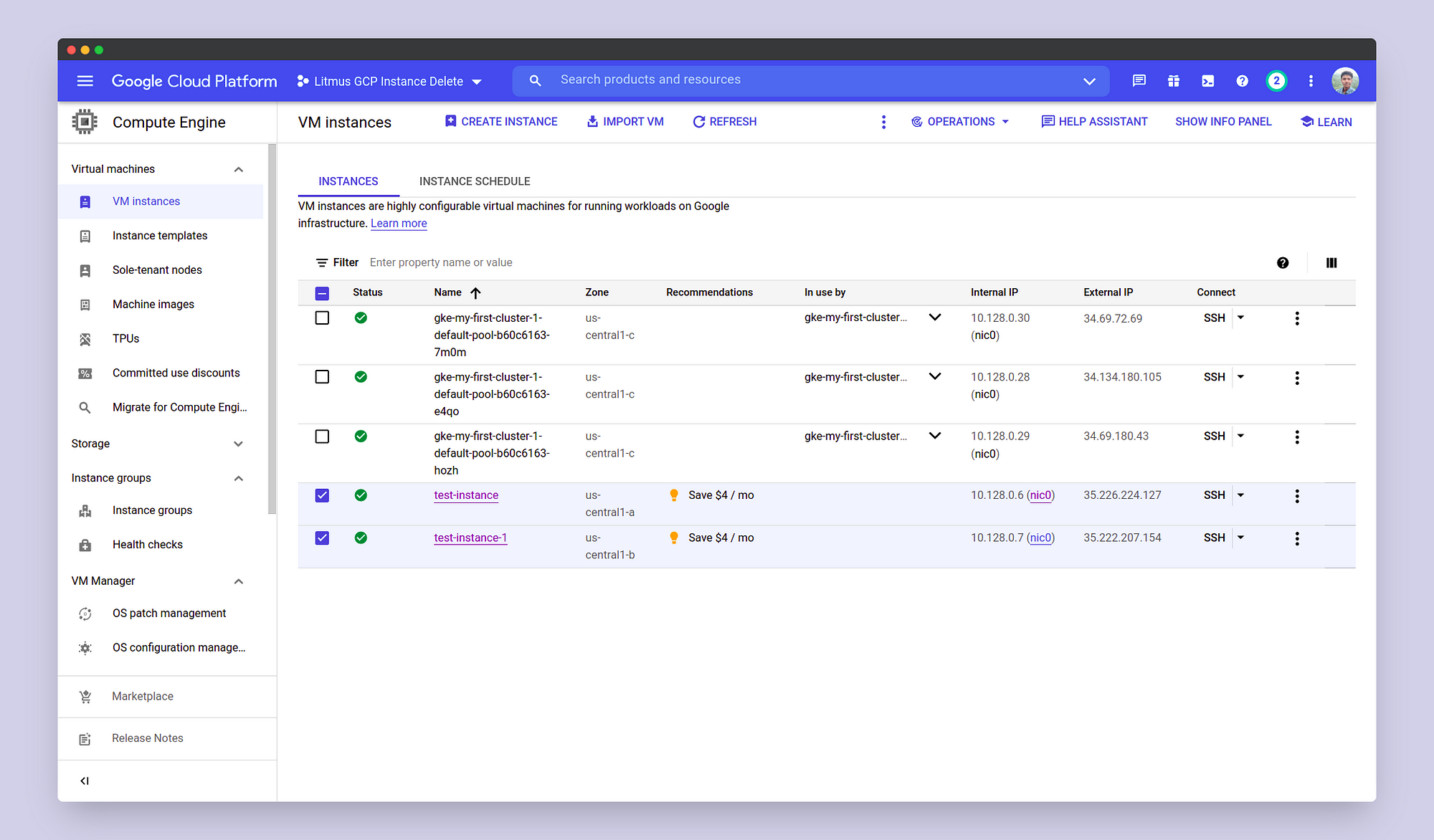
You can also determine if the chaos injection has taken place and as a result, the instances have shutdown or not from the GCP Console.
We can also view the Table View for the experiment logs as the experiment proceeds through the various steps.
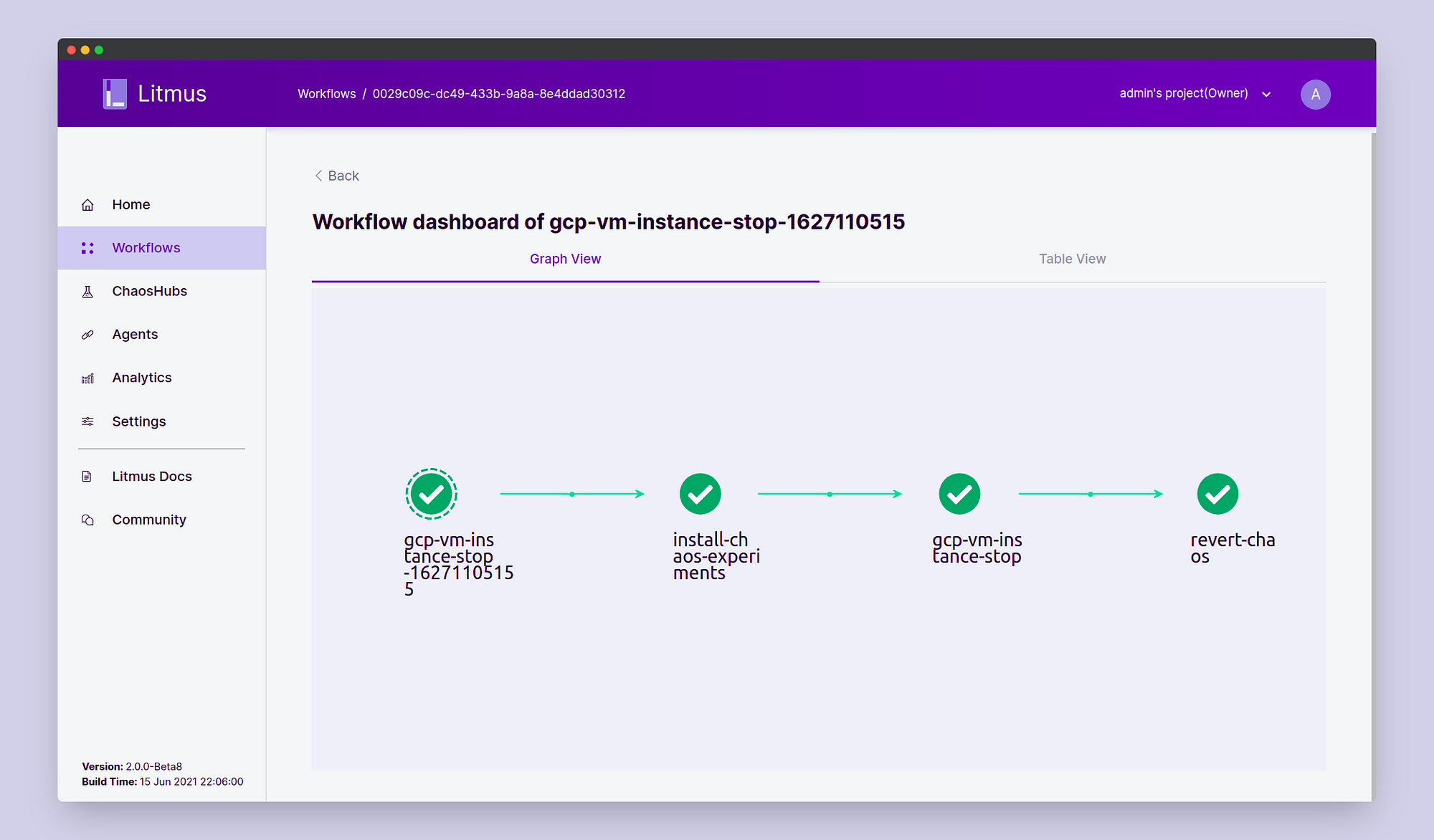
Once completed, the workflow graph should have executed all the steps successfully.
We can also check the ChaosResult verdict which should say the
experiment has passed. The Probe Success Percentage should be 100% as all
our instances restarted successfully post their shutdown.

Again you can check in the GCP console if the instances have restarted or not.
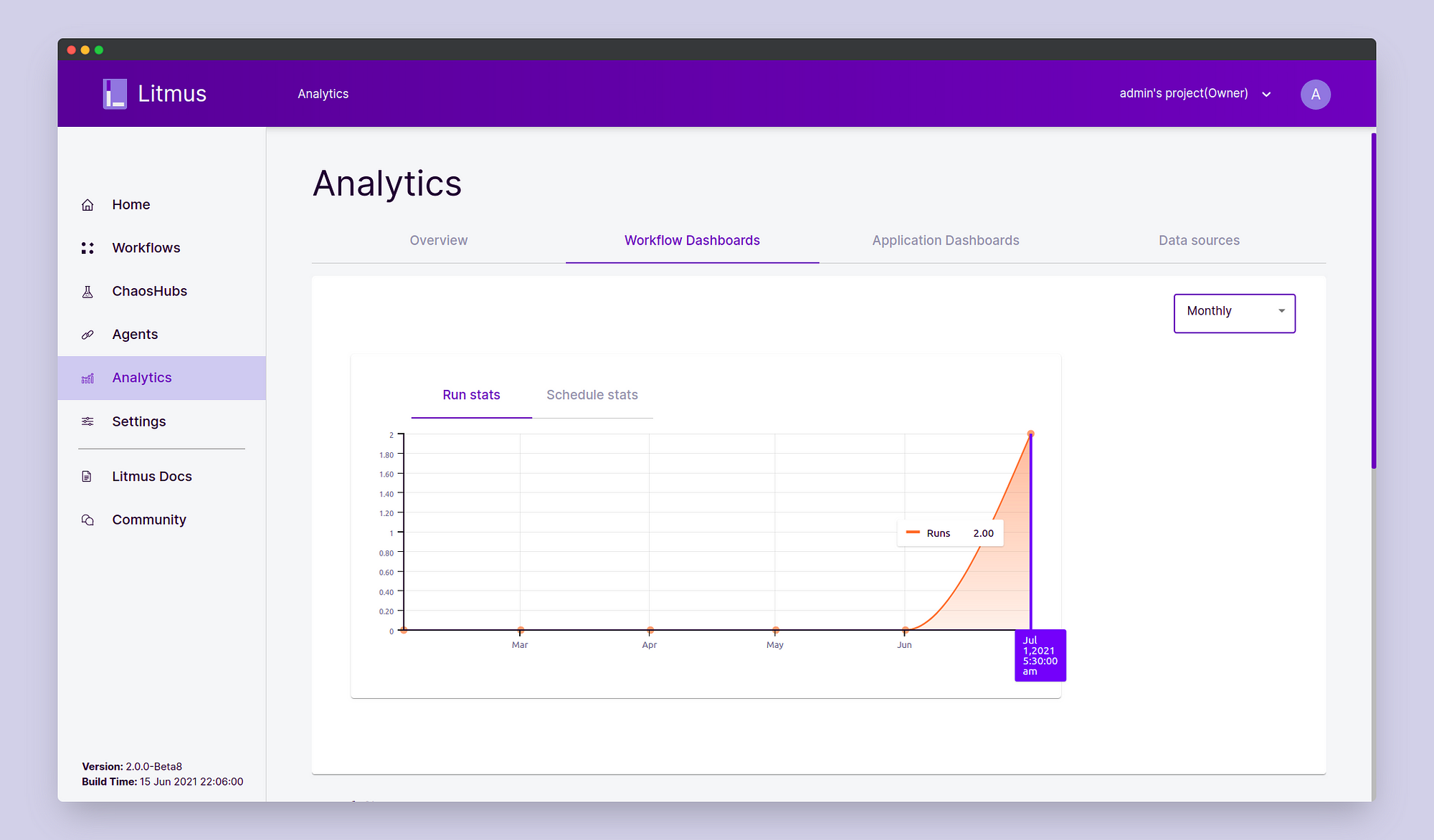
We can also perform post chaos analysis for the experiment results in the Analytics section.
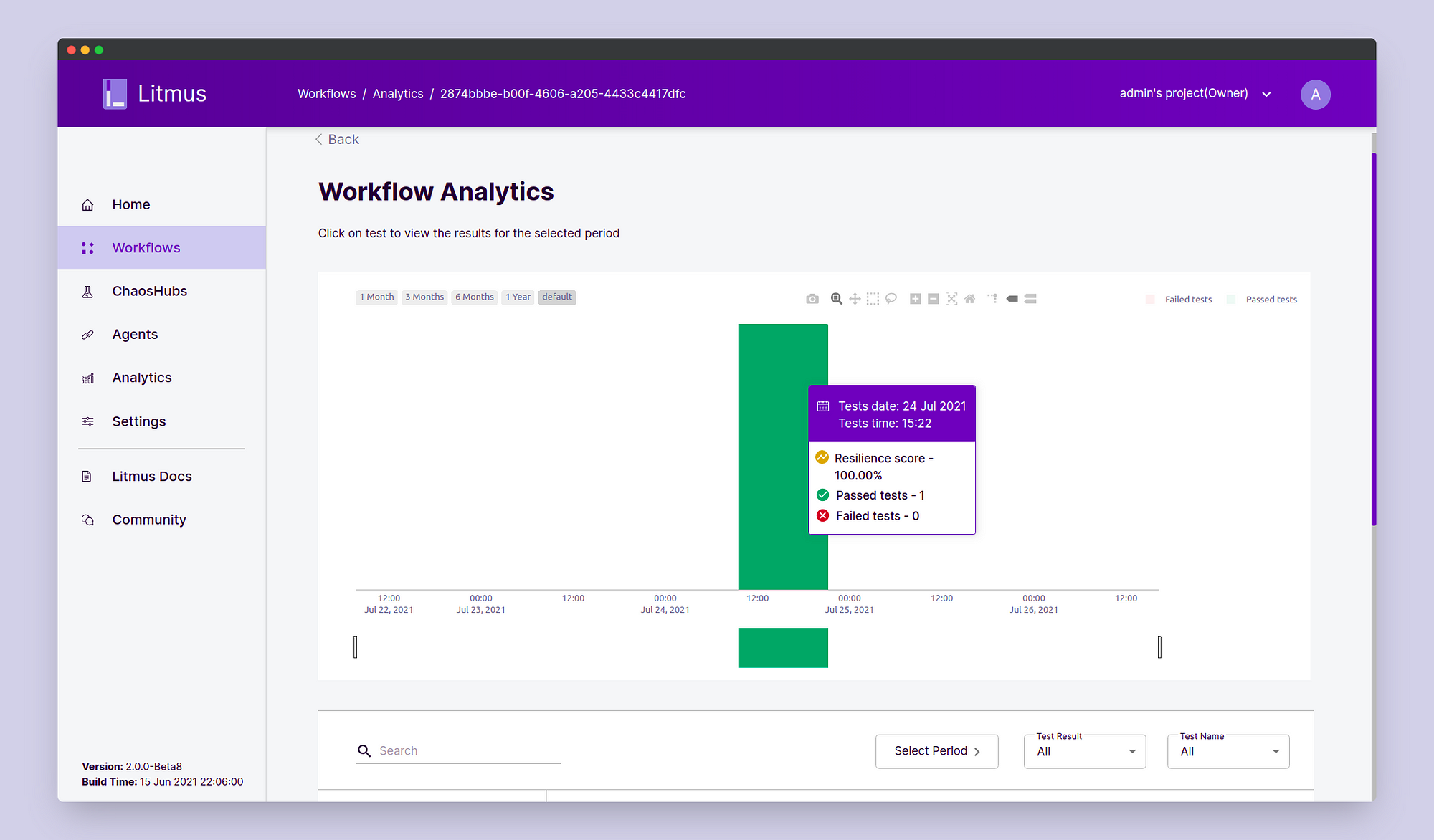
In conclusion of this blog, we saw how we can perform the GCP VM Instance Stop chaos experiment using Litmus Chaos 2.0. This experiment is only one of the many experiments for the Non-Kubernetes experiments in LitmusChaos, including experiments for AWS, Azure, VMWare, and many more, which are targeted towards making Litmus an absolute Chaos Engineering toolset for every enterprise regardless of the technology stack used by them.
Come join me at the Litmus community to contribute your bit in developing
chaos engineering for everyone. To join the Litmus community:
Step 1: Join the Kubernetes slack using the following link:
https://slack.k8s.io/
Step 2: Join the #litmus channel on the Kubernetes slack or use this
link after joining the Kubernetes slack:
[https://slack.litmuschaos.io/](https://slack.litmuschaos.io/)
Show your ❤️ with a ⭐ on our Github. To learn more about Litmus, check out the Litmus documentation. Thank you! 🙏