Aug 23, 2025
Building a Distributed Database from Scratch: The ConureDB Journey

When I set out to build ConureDB, I wanted to create something meaningful - a persistent, distributed key-value database that could serve as both a learning exercise and a production-ready system. The goal was ambitious: build something similar to etcd, with quorum-based consensus that could survive up to 50% of replicas failing. This blog chronicles the entire journey, from initial planning to the final Kubernetes deployment.
1. The Vision: A Resilient Distributed Database
The database landscape is dominated by a few key players, but understanding how they work internally requires building one yourself. I wanted ConureDB to have these characteristics:
- Persistent storage: Data should survive process restarts and system failures
- Distributed architecture: Multiple replicas working together for high availability
- Consensus-based: Using Raft algorithm for strong consistency guarantees
- Fault-tolerant: Surviving up to 50% node failures (N/2 - 1 failures in an N-node cluster)
- Production-ready: Complete with APIs, monitoring, and Kubernetes deployment
The inspiration came from etcd, which powers Kubernetes' control plane and has proven itself in countless production environments. However, building from scratch would give me complete control over design decisions and deep understanding of every component.
2. Choosing the Right Data Structure: The Storage Engine Decision
The heart of any database is its storage engine, and the choice of data structure fundamentally affects performance characteristics. I evaluated several options:
B-Tree

A B-tree is a self-balancing tree data structure that maintains sorted data and allows searches, sequential access, insertions, and deletions in logarithmic time. Unlike binary trees, B-trees can have multiple keys per node and more than two children, making them particularly well-suited for systems that read and write large blocks of data, such as databases and file systems. B-trees have been the backbone of databases for decades. They work by:
- Maintaining sorted order: Keys are always kept in sorted order, enabling efficient range queries
- Balanced structure: All leaf nodes are at the same depth, guaranteeing O(log n) operations
- Node-based organization: Data is organized in pages/nodes, typically matching disk block sizes
- Efficient for reads: Direct path from root to any key with minimal disk I/O
B-trees excel at
- Read performance: Logarithmic time complexity for point queries
- Range queries: Excellent for scanning ranges of keys
- Update efficiency: In-place updates with minimal structural changes
- Memory locality: Good cache performance due to node-based organization
LSM Tree

An LSM-tree (Log-Structured Merge-tree) is a data structure optimized for write-heavy workloads that maintains data across multiple levels of storage, typically starting with an in-memory component and cascading to disk-based structures. New writes are first stored in memory (often called a memtable), and when this fills up, it's flushed to disk as an immutable sorted file. Over time, these files are merged and compacted in a background process that combines smaller files into larger ones at different levels, maintaining sorted order while removing obsolete or deleted entries. This design provides excellent write performance since writes are sequential and buffered, though it trades off some read performance due to the need to potentially search multiple files.
- Write-optimized: All writes go to memory (memtable) first
- Immutable files: Data is organized in immutable, sorted files (SSTables)
- Compaction process: Background merging of files to maintain performance
- Write amplification: Trade-off where writes may be amplified during compaction
LSM trees are ideal for:
- High write throughput: Sequential writes to immutable files
- Append-heavy workloads: Perfect for time-series data or logging
- Compression: Immutable files can be heavily compressed
However, they have drawbacks:
- Read amplification: May need to check multiple files for a single key
- Compaction overhead: Background processes that consume I/O and CPU
- Write amplification: Data may be rewritten multiple times during compaction
Modern Alternatives: Bw-Trees and Hybrid Approaches
Bw-Tree
A Bw-tree (Buzz Word tree) is a lock-free B+-tree variant designed for high-performance, multi-threaded environments, particularly in main-memory database systems.
-
Instead of using traditional locks for concurrency control, the Bw-tree employs a mapping table that indirectly references tree nodes, allowing for atomic updates through compare-and-swap operations on pointers.
-
When modifications are needed, rather than updating nodes in-place, the structure creates delta records that are prepended to existing nodes, forming chains of changes that can be later consolidated during page reorganization.
-
This approach enables lock-free reads and writes while maintaining the sorted order and logarithmic search properties of B+-trees.
B-Tree and LSM Tree Hybrid
A hybrid key-value database can be designed to deliver high performance while supporting both LSM-tree and B+ tree data structures. It follows a log-structured approach and functions as an embedded DBMS, making it suitable for direct integration into applications without requiring a separate server process. LotusDB uses this approach.
-
The core idea is to combine the strengths of different indexing structures. LSM-trees excel in write-heavy workloads due to their sequential write patterns and compaction strategies, while B+ trees offer efficient point lookups and range queries, making them ideal for read-heavy scenarios. By supporting both, the database allows users to choose the most suitable structure based on workload characteristics.
-
As an embedded system, this type of database provides high-performance local storage with minimal operational overhead, positioning it as a more optimized and flexible alternative to traditional Go-based storage engines.
Advantages:
- Combine benefits of both B-trees and LSM trees
- Use LSM-like structure for writes with B-tree-like access patterns
- Attempt to minimize both read and write amplification
The Decision: Why B-Trees Won
After careful consideration, B-trees was chosen to be used for ConureDB because:
- Proven scalability: Used by PostgreSQL, MySQL InnoDB, and countless other systems
- Predictable performance: No surprise compaction storms or write amplification
- Excellent read performance: Critical for a consensus-based system where reads need to be fast
- Simpler implementation: More straightforward to implement correctly
- Better suited for consensus: Raft requires stable, consistent storage characteristics
The trade-off was potentially lower write throughput compared to LSM trees, but for a consensus-based system where consistency trumps raw write performance, this was acceptable.
3. Concurrency and Performance: Copy-on-Write and Node Pooling
Copy-on-Write: Lock-Free Concurrency
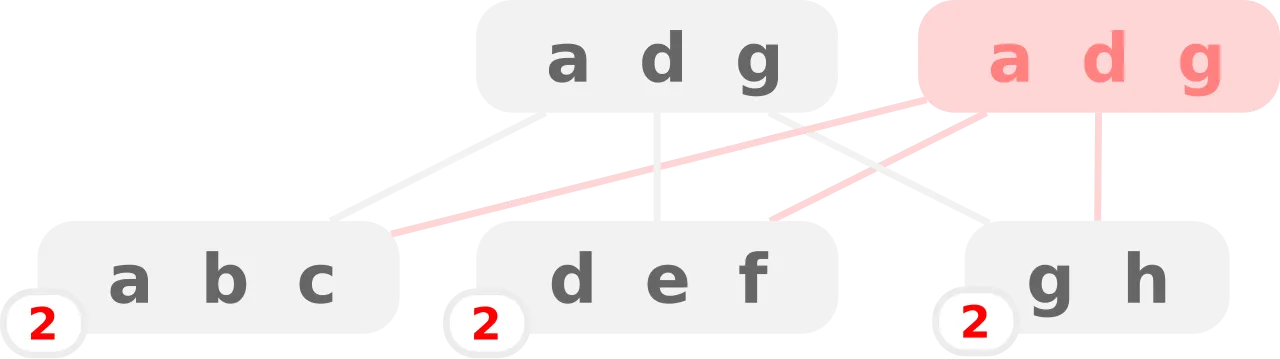
Traditional databases use complex locking mechanisms to handle concurrent access, but these can become bottlenecks. Copy-on-Write (CoW) is a technique used in databases and file systems to update a B-tree (or B+ tree) without modifying nodes in place. Instead of directly changing the existing tree, the modified nodes are copied, and references are updated to point to these new nodes.
- Immutable reads: Readers always see a consistent snapshot without locks
- Copy on modification: Writers create new versions of modified nodes
- Atomic updates: Root pointer updates make changes visible atomically
- Garbage collection: Old versions are cleaned up when no longer referenced
How It Works
- Read-only nodes remain unchanged → Only the path from the root to the modified leaf is copied.
- Modification → When inserting/updating/deleting a key, a new copy of the affected leaf (and any nodes on the path up to the root) is created.
- Re-linking → The new nodes are connected back to the existing unchanged parts of the tree.
- Root update → A new root pointer references the updated tree version, while the old root still points to the old version.
// Example: COW node modification func (t *BTree) insert(node *Node, key, value []byte) (*Node, error) { // Create a copy of the node (copy-on-write) nodeCopy, err := t.storage.CloneNode(node) if err != nil { return nil, err } // Modify the copy nodeCopy.AddItem(Item{Key: key, Value: value}) // Return new version return nodeCopy, nil }
Benefits of COW
- No read locks: Readers never block or get blocked
- Consistent snapshots: Each transaction sees a consistent view
- Simplified concurrency: No complex lock ordering or deadlock detection
- MVCC-ready: Natural foundation for multi-version concurrency control
Trade-offs
- Memory overhead: Multiple versions exist simultaneously
- Write amplification: Need to copy nodes even for small changes
- Garbage collection: Need to clean up old versions
Node Pooling: Optimizing Allocations
Database performance is often limited by memory allocation patterns. Node pooling is an optimization technique used to improve the performance and memory efficiency of B-tree (and B+-tree) implementations. Instead of constantly allocating and deallocating memory for nodes during inserts, deletes, and splits, the system maintains a pool of reusable nodes.
Here's the reasoning and mechanics:
Why node pooling?
- Reduce allocation overhead: Memory allocations in languages like Go can be expensive under high concurrency. Reusing nodes reduces GC pressure.
- Cache efficiency: Reusing recently freed nodes often keeps them in CPU caches, improving performance.
- Stability under churn: Workloads with frequent splits and merges (e.g., random inserts/deletes) benefit since they don't cause large amounts of garbage.
How it works
- Free list or pool: Maintain a pool (e.g., a lock-free queue or sync.Pool in Go) of previously used nodes.
- Node creation: When a new node is required (due to a split), the system first checks the pool; if a free node exists, it reuses it instead of allocating new memory.
- Node deletion/merge: When a node becomes unnecessary (e.g., after merging), instead of freeing it outright, the system returns it to the pool.
- Pool tuning: The pool may have a max size to prevent unbounded memory use; beyond that, excess nodes are released to the allocator.
type NodePool struct { nextNodeID NodeID freeNodeIDs []NodeID mu sync.Mutex } func (np *NodePool) Allocate() NodeID { np.mu.Lock() defer np.mu.Unlock() if len(np.freeNodeIDs) > 0 { // Reuse freed node ID nodeID := np.freeNodeIDs[len(np.freeNodeIDs)-1] np.freeNodeIDs = np.freeNodeIDs[:len(np.freeNodeIDs)-1] return nodeID } // Allocate new node ID nodeID := np.nextNodeID np.nextNodeID++ return nodeID }
Node Pool Benefits
- Reduced allocation overhead: Reuse existing node IDs
- Better memory locality: Nodes are allocated in predictable patterns
- Fragmentation reduction: Minimize memory fragmentation over time
- Faster operations: Avoid expensive allocation/deallocation syscalls
Storage Layer Optimizations
The storage layer includes several other optimizations:
-
Fixed-size pages: All nodes are stored in 4KB pages, matching typical filesystem block sizes for optimal I/O performance.
-
Memory-mapped I/O: Critical paths use memory mapping for better performance and simpler code.
-
Write-ahead logging: Although not fully implemented, the foundation exists for WAL-based durability.
-
Efficient serialization: Custom binary format optimized for the B-tree structure, avoiding JSON/protobuf overhead.
4. The Complete System: APIs, CLI, and Tooling
Beyond the core storage engine, ConureDB includes a complete ecosystem:
HTTP API Layer

The API layer provides RESTful endpoints for database operations:
GET /kv?key=mykey - Retrieve a value PUT /kv?key=mykey - Store a value (body contains the value) DELETE /kv?key=mykey - Delete a key GET /status - Health check and status GET /raft/config - Raft cluster configuration POST /join - Join a node to the cluster
The API layer handles:
- Leader routing: Automatically routes writes to the current Raft leader
- Consistency levels: Ensures reads reflect the latest committed state
- Error handling: Proper HTTP status codes and error messages
- Content negotiation: JSON responses with appropriate headers
Command Line Interface (CLI)

- Interactive shell for database operations
- Tab completion for commands
- Command history and editing
- Direct connection to any cluster node
Configuration and Deployment
The system supports flexible configuration:
# config.yaml example node_id: "node-1" data_dir: "/var/lib/conuredb" raft_addr: "node-1:7000" http_addr: "0.0.0.0:8081" bootstrap: false barrier_timeout: "30s"
Environment variable overrides allow easy containerization:
export CONURE_SEEDS="node-1:8081,node-2:8081,node-3:8081" export CONURE_NODE_ID="node-1"
5. Consensus with Raft: The Distributed Systems Heart
Understanding the Raft Algorithm
Raft solves the fundamental problem of distributed consensus; how do multiple machines agree on a shared state despite failures and network partitions?
Raft is a distributed consensus algorithm that helps a group of servers (or nodes) agree on a consistent state, even if some of them fail. It's most often used to manage a replicated log, which is the foundation for building fault-tolerant systems like databases, key-value stores, and configuration services.
Key ideas in Raft
Consensus problem
- In a distributed system, multiple nodes must agree on a single sequence of operations (e.g., writes to a database).
- The challenge is to do this correctly even if nodes crash, restart, or messages get delayed.
Leader-based approach
- Raft elects one node as the leader.
- The leader handles all client requests that modify the system state and replicates them to follower nodes.
- Followers are passive: they just replicate and respond to leader heartbeats.
Phases of Raft
- Leader election: If no leader exists, nodes vote to elect one. Majority wins.
- Log replication: The leader appends client requests to its log and replicates them to followers. Once a majority acknowledges, the entry is committed.
- Safety: Raft ensures logs are consistent across nodes. Even if leaders change, committed entries remain safe.
Fault tolerance
- Raft works as long as a majority of nodes (N/2 + 1) are available.
- Example: In a 5-node cluster, Raft tolerates 2 node failures.
The Raft State Machine
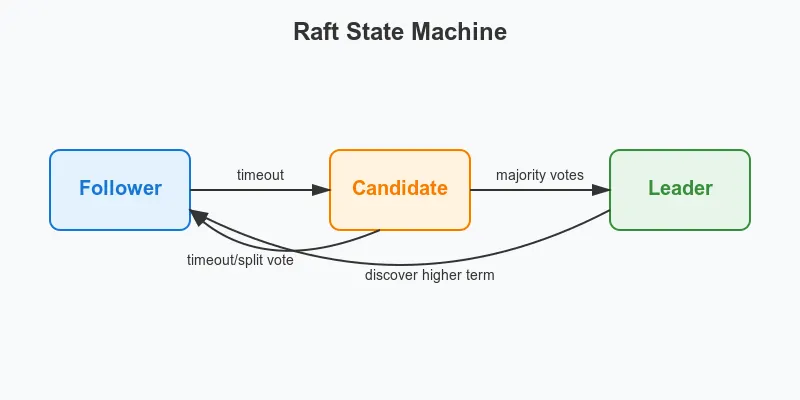
Leader Election Process:
- Followers timeout waiting for heartbeats
- Follower becomes candidate, increments term, votes for self
- Candidate requests votes from other nodes
- If majority votes received, becomes leader
- Leader sends heartbeats to maintain leadership
Log Replication:
- Client sends command to leader
- Leader appends entry to local log
- Leader sends AppendEntries RPCs to followers
- Followers append entry and send acknowledgment
- When majority acknowledges, leader commits entry
- Leader notifies followers of commitment in next heartbeat
Raft in ConureDB
ConureDB uses the HashiCorp Raft library, which provides a production-ready implementation:
// Raft configuration config := raft.DefaultConfig() config.LocalID = raft.ServerID(nodeID) config.HeartbeatTimeout = 1000 * time.Millisecond config.ElectionTimeout = 1000 * time.Millisecond config.CommitTimeout = 50 * time.Millisecond // Create Raft node r, err := raft.NewRaft(config, fsm, logStore, stableStore, snapshotStore, transport)
Finite State Machine (FSM): The FSM applies committed log entries to the database:
func (f *FSM) Apply(l *raft.Log) interface{} { cmd, err := DecodeCommand(l.Data) if err != nil { return err } switch cmd.Type { case CmdPut: return f.DB.Put(cmd.Key, cmd.Value) case CmdDelete: return f.DB.Delete(cmd.Key) default: return nil } }
Snapshots for Efficiency: To prevent log growth, Raft takes periodic snapshots:
func (f *FSM) Snapshot() (raft.FSMSnapshot, error) { return &dbSnapshot{db: f.DB}, nil } func (s *dbSnapshot) Persist(sink raft.SnapshotSink) error { return s.db.SnapshotTo(sink) }
Quorum Math: For a cluster of N nodes:
- Quorum size: (N/2) + 1
- Tolerated failures: (N-1)/2
- 3-node cluster: Tolerates 1 failure
- 5-node cluster: Tolerates 2 failures
Handling Network Partitions
Raft's design ensures safety during network partitions:
Split-brain prevention: Only one partition can have a majority, so only one leader can exist.
Consistency guarantees: Clients in the minority partition cannot write, ensuring consistency.
Automatic recovery: When partitions heal, nodes automatically rejoin and catch up.
6. Kubernetes Deployment: Production-Ready Operations
Helm Charts for Easy Deployment
ConureDB includes two Helm charts for different deployment scenarios:
Single Instance Deployment
For development or testing:
# charts/conuredb-single/values.yaml replicaCount: 1 image: repository: conuredb/conuredb tag: "latest" service: type: ClusterIP httpPort: 8081 raftPort: 7000 persistence: enabled: true size: 10Gi storageClass: "standard"
High Availability Deployment
For production with full consensus:
# charts/conuredb-ha/values.yaml replicaCount: 3 # or 5 for higher availability # StatefulSet ensures stable network identities statefulset: enabled: true # Headless service for peer discovery service: headless: enabled: true # Pod disruption budget prevents majority loss podDisruptionBudget: enabled: true minAvailable: 2 # Ensures majority always available
Kubernetes-Native Features
StatefulSets: Provide stable network identities (conure-0, conure-1, conure-2) essential for Raft cluster formation. Unlike Deployments that create pods with random names, StatefulSets guarantee predictable naming that persists across restarts. This is crucial for Raft because each node needs a stable identity that other nodes can reference consistently. When conure-1 restarts, it remains conure-1, allowing the Raft cluster to maintain its membership configuration.
Headless Services: Enable direct pod-to-pod communication for Raft traffic while maintaining service discovery. A headless service (with clusterIP: None) doesn't provide load balancing but instead returns DNS A records pointing directly to individual pod IPs. This is essential for Raft because:
- Direct communication: Raft nodes need to establish persistent connections to specific peers, not load-balanced connections
- DNS-based discovery: Pods can discover each other using predictable DNS names like
conure-0.conure-headless.default.svc.cluster.local - Port separation: The headless service allows Raft traffic (port 7000) to flow directly between pods while client traffic (port 8081) can still use a regular ClusterIP service
- Network topology awareness: Each Raft node knows exactly which physical pod it's communicating with, important for leader election and log replication
For example, when conure-1 needs to send a heartbeat to conure-2, it connects directly to conure-2.conure-headless:7000, bypassing any load balancer that might interfere with the persistent connection Raft requires.
Pod Disruption Budgets: Prevent Kubernetes from disrupting too many pods simultaneously, maintaining quorum. A PDB with minAvailable: 2 in a 3-node cluster ensures that during voluntary disruptions (like node maintenance or cluster upgrades), Kubernetes will never terminate more than one ConureDB pod at a time. This guarantees that the Raft cluster always maintains its quorum of 2 nodes, preventing service unavailability during maintenance windows.
Persistent Volume Claims: Ensure data persistence across pod restarts and rescheduling. Each StatefulSet pod gets its own PVC (e.g., data-conure-0, data-conure-1) that persists even if the pod is deleted and recreated. This is critical for Raft because each node's log and state must survive pod restarts. Without persistent storage, a restarted node would lose its Raft log and require a full snapshot transfer to rejoin the cluster.
Init Containers: Handle cluster bootstrapping and node discovery automatically. Init containers run before the main ConureDB container and ensure proper startup ordering. For example, voter pods use init containers to wait for the bootstrap pod's health endpoint (http://conure-bootstrap-0:8081/status) to return successfully before starting their own ConureDB process. This prevents race conditions where nodes try to join a cluster that doesn't exist yet.
Bootstrap Pod Design: Solving the Chicken-and-Egg Problem
One of the trickiest challenges in deploying a Raft-based system on Kubernetes is the bootstrap problem: how do you start the first node in a cluster when every node expects to join an existing cluster?
The Challenge:
- Raft clusters need at least one node to start (the bootstrap node)
- Multiple StatefulSets need coordinated startup to avoid race conditions
- Network timing and ordering must be handled gracefully
ConureDB's Two-StatefulSet Strategy:
ConureDB solves this using separate StatefulSets for different roles:
-
Bootstrap StatefulSet (
conure-bootstrap):- Creates a single pod (
conure-bootstrap-0) - Starts with
--bootstrap=trueflag - Establishes the initial cluster state
- Creates a single pod (
-
Voter StatefulSet (
conure):- Creates the remaining pods (
conure-0,conure-1, etc.) - Uses init containers to wait for bootstrap pod readiness
- Joins the cluster using seeds configuration
- Creates the remaining pods (
How It Works
The bootstrap process follows these steps:
- Bootstrap StatefulSet starts first and creates the initial cluster
- Voter StatefulSet init containers wait for bootstrap pod health checks to pass
- Once
conure-bootstrap-0is ready, voter pods start and join the cluster - The cluster reaches full consensus with all members participating
Key Benefits
- Deterministic Startup: Clear separation between bootstrap and joining phases
- Race Condition Prevention: Init containers ensure proper ordering
- Operational Simplicity: Bootstrap pod can be safely removed after cluster formation
- Rolling Update Safety: Updates work correctly without disrupting consensus
This design pattern is essential for production distributed systems because it eliminates the complexity of bootstrap detection logic while ensuring reliable cluster formation.
Network Delays: Init containers use retries and timeouts to handle network latency during startup.
Graceful Degradation: If bootstrap detection fails, nodes default to join mode, which is safer than accidentally creating multiple clusters.
Service Discovery and Auto-Join
ConureDB supports Kubernetes-native service discovery:
// Auto-discovery using Kubernetes DNS seeds := []string{ "conure-0.conure-headless:8081", "conure-1.conure-headless:8081", "conure-2.conure-headless:8081", } // Automatic cluster joining if !cfg.Bootstrap { go joinCluster(cfg.NodeID, cfg.RaftAddr, 2*time.Second, 0) }
Benefits of Kubernetes Integration:
- Automatic scaling: Easy to add/remove nodes
- Health monitoring: Kubernetes health checks and restart policies
- Load balancing: Automatic traffic distribution
- Rolling updates: Zero-downtime deployments
- Resource management: CPU and memory limits/requests
Conclusion: Lessons Learned and Future Directions
Building ConureDB from scratch was an incredible learning experience that reinforced several key principles:
Simplicity wins: Choosing B-trees over more exotic data structures paid off in implementation simplicity and debuggability.
Consensus is complex: Even with a mature Raft library, distributed consensus introduces many edge cases and operational complexities.
Copy-on-write is powerful: COW semantics simplified concurrency while maintaining good performance characteristics.
Operational tooling matters: The database is only as good as its deployment, monitoring, and management tools.
Performance optimization is iterative: Starting with a correct implementation and optimizing bottlenecks as they appear is more effective than premature optimization.
Final Thoughts
Building a database from scratch demystifies the "magic" behind systems we use every day. While ConureDB may not replace production databases anytime soon, the journey of building it provides invaluable insights into distributed systems, storage engines, and the engineering trade-offs that shape our digital infrastructure.
The complete source code, documentation, and deployment guides are available on GitHub, ready for anyone brave enough to continue this journey of database exploration and learning.